

The Built-in VTScada Historian
This SCADA Historian is a fully-integrated component of VTScada software included at no additional cost and requiring no configuration or database management.

The historical database is configured automatically to match the number of tags logging data to it. Easy-to-use interfaces allow for creation of trend displays, tabular data displays and data export. Third-party software connectors offer simple connectivity for external data use by enterprise systems (e.g. reporting, maintenance management, analysis, etc).
Introduced in VTScada 11.3.14 – When replacing another SCADA software application with VTScada, you can now keep all your historical data.
A Fast Compact Database Schema
This SCADA Historian is pre-configured in every application and has a standardized schema. The integrated database is stored in binary files, which results in very compact storage and fast data read/write access.
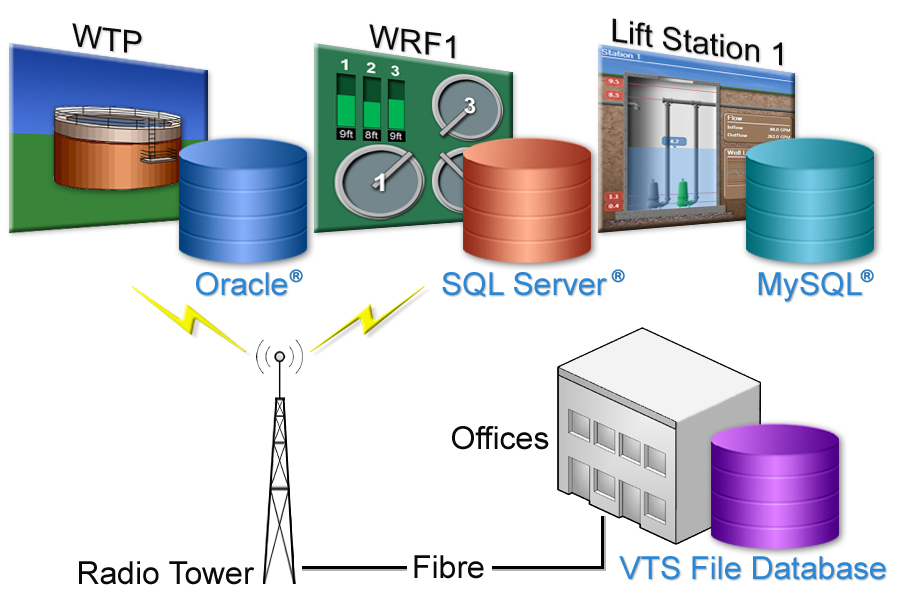
Relational databases can be used as an alternative to file-based storage. Microsoft SQL, Oracle and MySQL are optional databases. They must be purchased separately and are installed and configured as per the respective manufacturers’ instructions. A script is provided with VTScada to automatically configure the schema if using one of these alternatives.
Log Data from Multiple Sources

Log Data Based on Triggers
- Log on change with user-configurable deadband (default)
- Related event (can also be used for disable/enable)
- Log on time/sample period
- Operator actions (e.g. Entry of a manual value into a numeric data entry field, change of a setpoint, or a control action)
Data is stored directly to the Historian at the time of trigger occurrence. This eliminates any need for separate real-time and historical databases.
Simple Historian Status Monitoring
The Historian Status Monitoring Widget provides instant status of write and storage rates. When write rates exceed storage rates, data is automatically buffered and written in burst mode when the Historian connection is available. VTScada write rates have been tested to 4,000 values per second for a single tag, thus buffering is usually the result of a slow network, underpowered CPU, or slow storage media.
Summary, On-Demand Data
Upon request, VTScada analyzes raw tag data and provides the following time-series summary data, based on a user-definable duration divided into time slices (e.g. one day’s data divided into one hour slices):
- Time-weighted average (analog)
- Minimum (analog)
- Maximum (analog)
- Change in value (analog)
- Value at start (analog)
- Time of Minimum (analog)
- Time of Maximum (analog)
- Totalizer (analog)
- Interpolated (analog)
- Diff between start and end (analog)
- Zero to non-zero transitions (digital)
- Non-zero time (digital)
Database Size, Storage Limiting, and Data Retention Periods
VTScada supports the same number of I/O tags as the licensed SCADA server with which it is integrated. Calculated values logged to the Historian do not count against the total tag count.
The Historian will automatically grow in total storage size to that available on the available drives. Where additional space is required, increasing the space available to a logical drive will automatically make that space available to the Historian.
Due to the efficient size of the Historian’s native binary data file format and the low cost of large storage, the Historian is configured to keep all data by default. However, where storage space is limited, the Historian can be configured to automatically delete data older than X days or keep a specific number of records for each tag. Data is overwritten based on a First-In-First-Out (FIFO) methodology.
 Multiple SCADA Historian Configuration
Multiple SCADA Historian Configuration
Any number of Historians can be created for a single application. Different Historians may be configured to store data for a different period or number of records per tag. The Historians may use similar or different data storage formats. For example Historian #1 may use the file-based storage and Historian #2 may use MS SQL Server or another relational database. Each tag may store data to one Historian.
Redundant SCADA Historian Configuration
Since our Historian is an integrated component of any VTScada Runtime or Development Runtime license, any computer running one of these licenses can be configured as a Historian server (e.g. primary, backup, 2nd backup, 3rd backup, etc).

Redundant SCADA Historians may also use similar or different data storage formats, for example the Primary Historian may use the file-based storage and the Backup Historian may use Oracle or another relational database. Each data point will be stored exactly the same on each redundant Historian. Redundant Historians may be co-located with the Primary Historian or may be geographically separated as long as an IP connection exists between the two.
 Redundant Historian Data Synchronization and Data Backfill
Redundant Historian Data Synchronization and Data Backfill
All redundant SCADA Historians will be identical with regard to the same schema and a complete, replicated copy of all data. Timestamps will be matched for each data-point to the millisecond.
Should the primary database server fail, associated workstations and Internet clients switch to the next designated database. When it is restored, historical data automatically synchronizes across a local or wide area network at up to 160,000 values per second. This speed is automatically throttled such that real-time communications between SCADA servers is not significantly deteriorated.
Any data on any Historian that is missing on another will be propagated automatically regardless of how long it has been since the databases have communicated.
Long Term Data Storage (eliminates archiving)
In the SCADA industry, archiving is typically adopted for long-term historical data storage due, in part, to a) a lack of online drive space, and b) to ensure data was backed up in the event of Historian failure.
VTScada eliminates the need for data archiving. VTScada’s efficient binary storage eliminates online drive space issues allowing the size of the database to scale as required utilizing the drive space available. New space can be added to the logical drive with the addition of a new physical driver providing unlimited scalability for the Historian.
Establishing redundant SCADA Historians is a far more robust backup methodology, allowing any number of backup databases to be updated in real time.
More Information
- The VTScada Historical Data Viewer displays continuous real-time and historical data.
- VTScada’s ODBC Server and OPC Client/Server allow you to share data with third-party software.